Why Your AI App Needs a Gateway Layer
What an LLM gateway does, why it matters, and how it lets you ship AI features faster by abstracting away provider complexity.
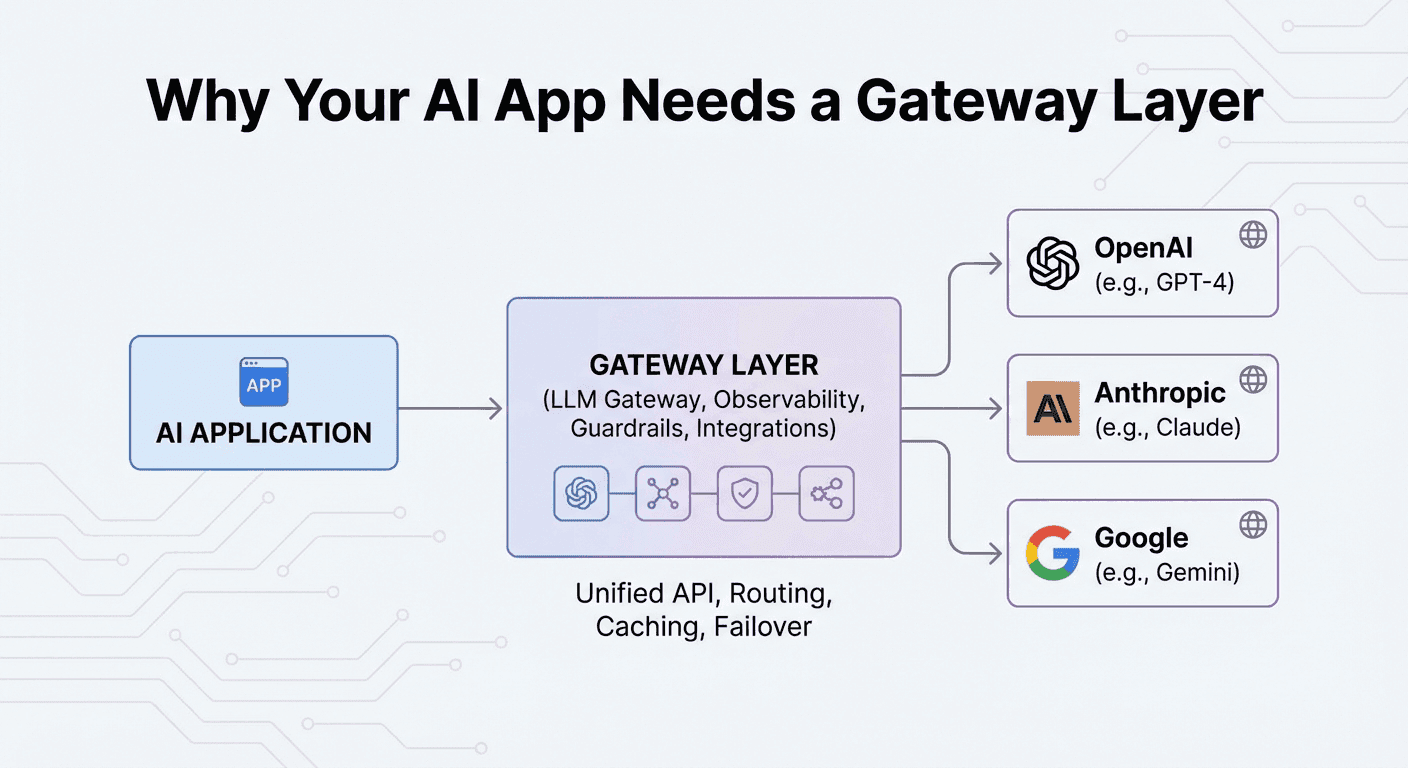
You don't want to manage LLM providers. You want to ship AI features.
An LLM gateway is the layer between your application and the model providers that handles the operational complexity so you can focus on building. Here's what that actually means and why it matters as your AI application scales.
What Is an LLM Gateway?
An LLM gateway is a unified API layer that sits between your application and LLM providers like OpenAI, Anthropic, and Google. Instead of integrating directly with each provider's SDK, you integrate once with the gateway and access every provider through a single, consistent interface.
1Your App → LLM Gateway → OpenAI2 → Anthropic3 → Google4 → Meta5 → Mistral6 → 35+ more providers1Your App → LLM Gateway → OpenAI2 → Anthropic3 → Google4 → Meta5 → Mistral6 → 35+ more providersThink of it like a CDN for AI. A CDN abstracts away the complexity of content delivery — caching, edge routing, failover. An LLM gateway does the same for AI requests — routing, caching, observability, and failover across providers.
The Five Jobs of a Gateway
1. Unified API
Every LLM provider has a different API format. Different SDKs, different authentication, different request/response shapes. A gateway normalizes this into a single interface.
With LLM Gateway, you use the OpenAI-compatible chat completions format for every provider:
1# This works for OpenAI, Anthropic, Google, and every other provider2curl https://api.llmgateway.io/v1/chat/completions \3 -H "Authorization: Bearer YOUR_API_KEY" \4 -H "Content-Type: application/json" \5 -d '{6 "model": "anthropic/claude-sonnet-4-5",7 "messages": [{"role": "user", "content": "Hello"}]8 }'1# This works for OpenAI, Anthropic, Google, and every other provider2curl https://api.llmgateway.io/v1/chat/completions \3 -H "Authorization: Bearer YOUR_API_KEY" \4 -H "Content-Type: application/json" \5 -d '{6 "model": "anthropic/claude-sonnet-4-5",7 "messages": [{"role": "user", "content": "Hello"}]8 }'One integration. Every model. No provider-specific code.
2. Request Routing
Not every request needs the same model. A gateway can route requests to different models based on complexity, cost targets, or specific capabilities:
- Route simple classification tasks to budget models ($0.10/M tokens)
- Send complex reasoning to flagship models ($5-10/M tokens)
- Direct vision tasks to models with image understanding
- Split traffic for A/B testing different models
Without a gateway, you'd build this routing logic yourself and maintain it as models and pricing change. With a gateway, it's configuration.
3. Caching
Many LLM requests are repetitive — especially in production. FAQ responses, template generations, and classification tasks often produce identical outputs for identical inputs.
Gateway-level caching means:
- Repeated requests return instantly from cache
- Zero token cost for cached responses
- Typical cache hit rates of 15-30% in production
That's an immediate cost reduction and latency improvement with no code changes.
4. Observability
When you're calling multiple providers across multiple projects, you need visibility into what's happening:
- Cost tracking per model, per project, per API key
- Latency monitoring to catch slowdowns before users notice
- Usage analytics to understand traffic patterns
- Error tracking to identify failing requests
A gateway centralizes this data instead of forcing you to check each provider's dashboard separately.
5. Failover
Providers go down. Rate limits get hit. Models get deprecated. A gateway handles all of this:
- Automatic retries on transient failures
- Provider fallback when a primary provider is unavailable
- Graceful degradation so your app stays up even when a provider doesn't
Without failover, a single provider outage takes down every AI feature in your application. With it, your users don't even notice.
When You Don't Need a Gateway
If you're prototyping, using a single model, and don't care about costs yet — just call the provider directly. Adding infrastructure before you need it is over-engineering.
You start needing a gateway when:
- You're using more than one model or provider
- LLM costs are becoming a meaningful line item
- You need visibility into usage and spending
- Reliability matters (it's in production and users depend on it)
- You want to experiment with different models without code changes
When You Do Need One
Most production AI applications hit at least three of those criteria. At that point, a gateway isn't overhead — it's infrastructure that pays for itself through cost savings, reliability, and developer time saved.
The alternative is building it yourself: a routing layer, a caching layer, provider adapters, failover logic, cost tracking, and a dashboard to see it all. That's months of engineering work on infrastructure instead of features.
Getting Started
LLM Gateway gives you all of this with a single API endpoint. Connect your existing OpenAI SDK, change the base URL, and you're running through the gateway.
1import OpenAI from "openai";2
3const client = new OpenAI({4 apiKey: "YOUR_GATEWAY_API_KEY",5 baseURL: "https://api.llmgateway.io/v1",6});7
8// Use any of 200+ models from 40+ providers9const response = await client.chat.completions.create({10 model: "gemini-2.5-flash",11 messages: [{ role: "user", content: "Hello!" }],12});1import OpenAI from "openai";2
3const client = new OpenAI({4 apiKey: "YOUR_GATEWAY_API_KEY",5 baseURL: "https://api.llmgateway.io/v1",6});7
8// Use any of 200+ models from 40+ providers9const response = await client.chat.completions.create({10 model: "gemini-2.5-flash",11 messages: [{ role: "user", content: "Hello!" }],12});