Q2 2026: Speech, Embeddings & Coding Plans
Three months of updates: speech generation and Audio Studio, OpenAI-compatible embeddings, OCR, DevPass coding plans, chat subscription plans, enterprise IAM and master keys, SOC 2 Type II, 40+ new models, and much more.

Most teams want one API for everything they build with — text, speech, embeddings, images, video — without juggling a separate vendor and SDK for each. Q2 was about closing that gap. LLM Gateway added speech generation and embeddings as first-class OpenAI-compatible endpoints, shipped fixed-price coding plans and chat subscriptions, tightened enterprise access controls, earned SOC 2 Type II, and brought 40+ new models online. Here's everything that shipped from April through June.
By the Numbers
The quarter in traffic, across every project on the platform:
- 27,038,440 requests routed
- 207.9B tokens processed — 195.8B input, 120B cached, 11.8B output
DeepSeek V4, Grok 4.1 Fast, and Gemini 3 Flash drove the most volume. But the bigger story is how much of it is no longer plain text: Gemini Embedding 2 ranks second by request count, and GPT Image 2 lands in the top ten — proof that embeddings, images, and audio now move serious traffic through the gateway.
Top 10 models by tokens
| # | Model | Tokens |
|---|---|---|
| 1 | deepseek-v4-pro | 48.6B |
| 2 | grok-4-1-fast-non-reasoning | 29.2B |
| 3 | gemini-3-flash-preview | 27.0B |
| 4 | deepseek-v4-flash | 23.0B |
| 5 | claude-sonnet-4-6 | 7.7B |
| 6 | claude-opus-4-8 | 6.4B |
| 7 | gemini-3-pro-image-preview | 6.2B |
| 8 | gemini-embedding-2 | 5.8B |
| 9 | glm-5.2 | 5.1B |
| 10 | claude-opus-4-6 | 4.6B |
Top 10 models by requests
| # | Model | Requests |
|---|---|---|
| 1 | grok-4-1-fast-non-reasoning | 10,605,050 |
| 2 | gemini-embedding-2 | 5,887,455 |
| 3 | gemini-3-flash-preview | 2,406,179 |
| 4 | gemini-3-pro-image-preview | 2,122,872 |
| 5 | deepseek-v4-flash | 1,158,043 |
| 6 | gemini-3.1-flash-image-preview | 668,547 |
| 7 | gpt-image-2 | 543,958 |
| 8 | deepseek-v4-pro | 540,795 |
| 9 | grok-4-1-fast | 300,313 |
| 10 | deepseek-v3.2 | 289,820 |
Speech & Audio

Text-to-speech now runs through the same gateway as the rest of your stack:
/v1/audio/speech— An OpenAI-compatible speech endpoint backed by ElevenLabs, Google Gemini, and more, so you switch voices and providers without changing your code.- ElevenLabs provider — Native text-to-speech with per-character pricing tracked on every request.
- Google audio — Audio support for Google models, wired into the Playground.
- Audio Studio — A dedicated workspace in the Playground for generating and previewing speech.
Embeddings

/v1/embeddings is now OpenAI-compatible across providers, so retrieval and semantic search work without provider-specific glue:
- Google embeddings via
gemini-embedding-001, plus Google Vertex embeddings - Same-provider key fallback — Embedding requests fail over to your other keys on the same provider
- Routing metadata and key health included in embedding responses, just like chat completions
OCR
/v1/ocr— Extract structured text from documents and images withmistral-ocr-latest.- Chat OCR — The Playground reads text out of uploaded images directly in a conversation.
Video Generation

We expanded video beyond Q1's launch with new models and input modes:
- ByteDance Seedance 2.0, 2.0 Fast, and 1.5 Pro — including reference-video input and first/last-frame control on Seedance 2.0
- Alibaba Wan 2.6 — text-to-video
- MiniMax Hailuo 2.3
- AtlasCloud Kling v3
- Grok Imagine Video 1.5 — promoted out of preview
Image Generation
- gpt-image-2 — Added from OpenAI and via Azure OpenAI, with quality and size pass-through for accurate, resolution-based pricing.
- Reve — A new image-generation provider.
Responses API
/v1/responses— Full support for OpenAI's Responses API./v1/responses/compact— A compact variant for smaller payloads.item_referenceresolution — Input items referenced by ID are resolved server-side.
DevPass: Coding Plans
DevPass gives you a fixed monthly price for coding agents like Claude Code, Codex, Cline, and Cursor — frontier models without metered per-token billing. Q2 turned it into a complete product:
- Restricted to coding agents and root-model routing — Plans cover inference for supported agents, keeping pricing predictable
- Annual billing alongside monthly
- Invoices and shared billing details across the dashboard
- Public DevPass profiles to show off what you've built
- Social and passkey sign-in
- Cancellation feedback flow and lifecycle notifications
- New integration guides for Pi, Continue, Hermes, and Cursor plan mode
Chat Subscription Plans & Playground

The chat Playground gained Starter, Plus, and Pro subscription plans plus a wave of workflow features:
- Forking, message editing, and chat reset — Branch a conversation or rewind it
- Temporary chats that leave no history, and pinned chats in the sidebar
- Public share links with a redesigned share dialog and OpenGraph images
- Chat history search across every conversation
- Comparison mode persistence — Your multi-model setup sticks between sessions
- AI chat support replacing Crisp, with suggested answers and one-click human escalation
- Image, Video, and Audio Studios plus a Canvas page for longer-form work
Routing & Reliability
Routing got smarter about cost, latency, and stickiness:
- Per-request and per-project routing strategy — Choose how the gateway picks providers at either level
- Sticky session routing via the
x-session-idheader, so a conversation stays on one provider - Stable preferred-provider routing for predictable provider selection
- Image-aware token estimates feed auto-routing for more accurate cost weighting
- Provider service tiers — Flex and priority tiers (including Vertex), gated to your own provider keys
- Faster provider-downtime reaction and AWS Bedrock region routing with a global default
Enterprise & Security

- SOC 2 Type II — LLM Gateway completed its SOC 2 Type II audit. Read the announcement
- IAM rules — Restrict API keys by IP CIDR range (Enterprise)
- Master keys — Provision and manage keys programmatically, with dedicated IAM rule routes
- Per-key custom model catalog — Enterprise organizations expose a curated model list per key
- Per-project routing overrides — Pin providers and policies at the project level
- Provider compliance policies and legal metadata surfaced per provider
- Guardrails redact action — Mask sensitive content instead of blocking it outright
- Enterprise trial and lifted seat, project, and key limits for enterprise plans
API Key Lifecycle
- TTL expiration — Set an expiry on any API key
- Roll secret — Rotate a key's secret without changing its ID or breaking integrations
- See our API key rotation guide for the full pattern
Embeddable Payments SDK
For platforms that resell or meter LLM usage to their own users:
- Embeddable end-user wallets — Give your users their own credit balances
- SDK settings and sandbox test keys for safe local development
- Opt-in preview behind a feature flag
New Models
Q2 added more than 40 models across providers:
Anthropic
- Claude Opus 4.8 (Anthropic and AWS Bedrock)
- Claude Opus 4.7 with adaptive thinking
- Adaptive thinking for Opus 4.6
- Claude Sonnet 4.6 with a 1M-token context window
- Claude Fable 5 (Anthropic and AWS Bedrock)
OpenAI
- GPT-5.5 family
- gpt-image-2 (OpenAI and Azure OpenAI)
xAI
- Grok 4.3 and Grok Build 0.1, plus grok-4.20 via Vertex AI
- Grok Imagine Video 1.5
DeepSeek
- DeepSeek V4 Pro and V4 Flash across Alibaba, Novita, and CanopyWave
- DeepSeek V4 in Alibaba's Singapore region
- Reasoning enabled for DeepSeek V3.2 on Novita
Open & Frontier Models
- GLM-5.1 and GLM-5.2 across Z.ai, EmberCloud, Together AI, and Novita
- Kimi K2.6, K2.7 Highspeed, and K2.7 Code across Moonshot, CanopyWave, Novita, and Together AI
- MiniMax M3 and tool calling on MiniMax M2.7
- Qwen3.6 (Max Preview, Plus, 35B-A3B) and Qwen3.7 (Max, Plus) across Alibaba and Novita
- Gemma 4, Gemini 3.5 Flash, and Gemini 3.1 Flash Lite
- Nemotron 3 Ultra 550B, Xiaomi MiMo, and Sakana fugu-ultra
New Providers
- ElevenLabs — Text-to-speech
- Reve — Image generation
- DeepInfra — Inference provider
- Bluestone and extended Together AI coverage
- vertex-anthropic and a discounted anthropic-discount provider
- Azure AI Foundry — Grok models,
gpt-oss-120b, and custom Foundry deployment names - Vertex AI partner models — 13 new OpenAI-compatible mappings
Analytics & Admin
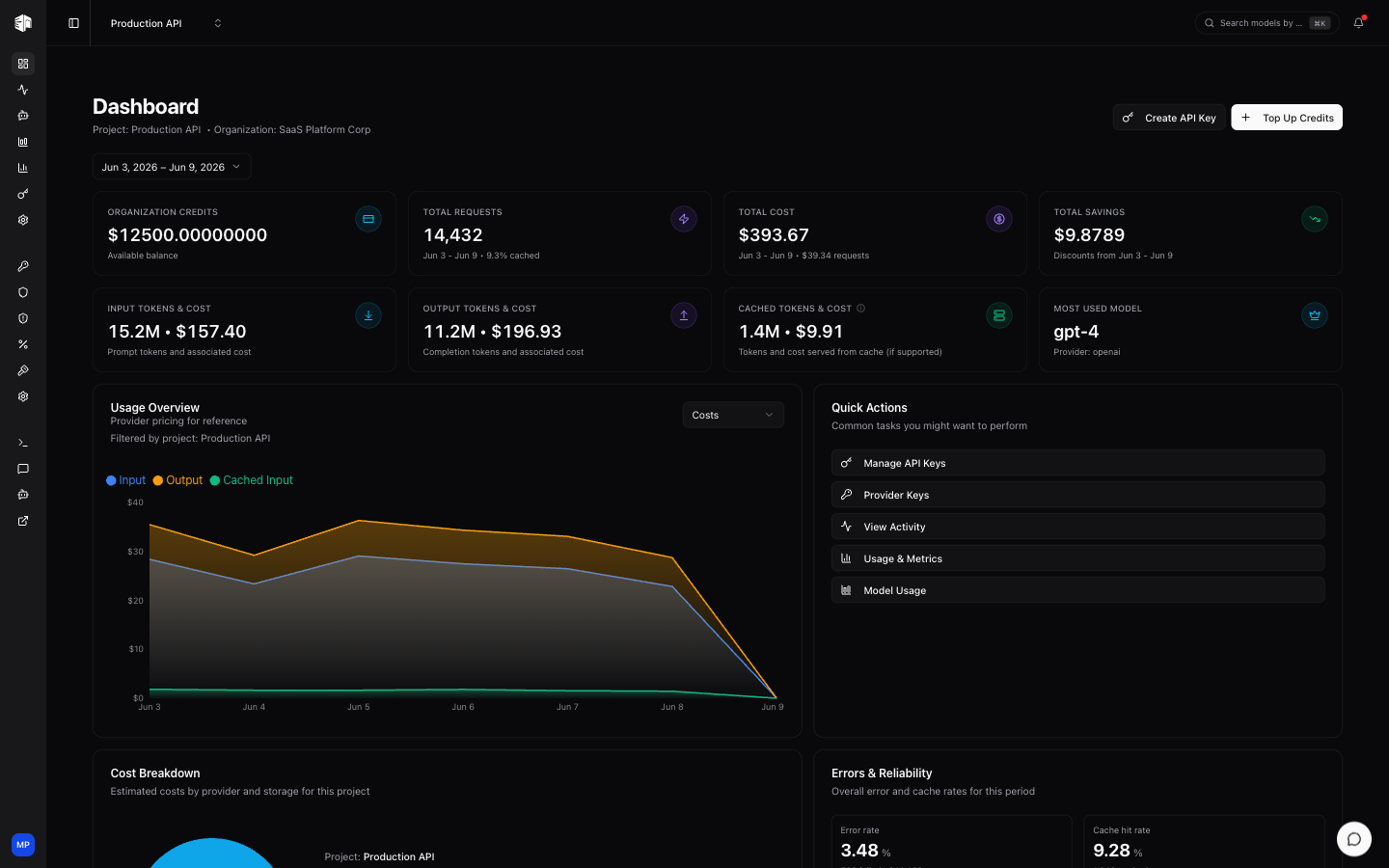
- Organization analytics — Member, API-key, and per-source usage breakdowns
- Hourly history rollups — Faster long-range charts, with hourly buckets beyond 24 hours in the admin dashboard
- Model categorization and weekly fair-use caps for premium-tier models
- A steady stream of admin dashboard improvements: cost-share views, sortable provider tables, error breakdowns by source, and custom date ranges
Billing & Payments
- Cache-write billing for Anthropic, AWS Bedrock, and Alibaba
- International payment fee handling
- Credit top-up minimum raised to $10
Deployment
- Helm chart — Self-host LLM Gateway on Kubernetes with a maintained chart. See the self-hosting guide.
Docs, SEO & Comparisons
- Fumadocs upgrade with Ask AI — Ask questions against the docs in natural language
- Enriched
llms.txtand a sitemap page for AI crawlers - Refreshed comparison pages with provider logos and OpenGraph images
- Community model ratings — Rate any model after 100 requests
- New enterprise SEO pages and a growing library of guides